Showing all 61 hot projects
AI4EDI
AI technologies to tackle EDI related issues

CARRE
Personalised patient empowerment for cardiorenal comorbidities

Catalyst
Collective Applied Intelligence and Analytics for Social Innovation: Open Tools Validated in Large-Scale Communities

CityLABS
Research and Innovation in the Digital Economy

Co-Inform
Co-Creating Misinformation-Resilient Societies

COMPOSE
Collaborative Open Market to Place Objects at your Service

COMRADES
Collective Platform for Community Resilience & Social Innovation During Crises


COVID-19 Research
A view of our labs response to the pandemic

DecarboNet
A Decarbonisation Platform for Citizen Empowerment and Translating Collective Awareness into Behavioural Change

DECIDE
DECIDE - Delivering Enhanced Biodiversity Information with Adaptive Citizen Science and Intelligent Digital Engagements


DiggiCORE
Digging into Connected Repositories


Election Debate Visualization
The EDV Project will provide radically new ways for the public to replay the televised debates from the next UK general election



FIT4RRI
Fostering Improved Training Tools for Responsible Research and Innovation




Human-Computer Collaborative Learning in Citizen Science
This project explores the potential for collaborative learning between humans and machines within the framework of environmental citizen science.

IMPAQT
Intelligent management system for integrated multi-trophic aquaculture



Listening Experience Database
A crowd-sourced linked data resource of documented experiences of listening to music


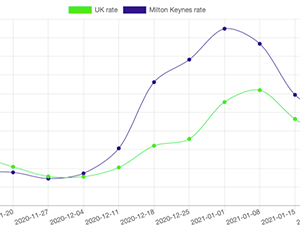
MK:Smart
An innovation programme developing sustainable smart solutions for Milton Keynes

ON-MERRIT
Observing and Negating Matthew Effects in Responsible Research and Innovation Transition


Open Networking Lab
Practical learning about computer networking

OpenLang Network
A language learning network for Erasmus+ KA1 mobility participants
OpenSTEM Africa Blockchain
Leveraging Blockchain for OpenSTEM Africa
Organised Crime Group Mapping
Analysing methods for assessing the risk of organised crime

OU Analyse
The OU Analyse project is piloting new machine learning based methods for early identification of students who are at risk of failing.


Polifonia
A digital harmoniser of European musical heritage
QualiChain
Decentralised Qualifications' Verification and Management for Learner Empowerment, Education Reengineering and Public Sector Transformation
RAE (Responsive Algorithmic Enterprise)
Energy management system for SMEs

REF 2021 Predictions
Web-scale research analytics for identifying high performance and trends: data-driven approaches to Scientometrics.

Robot Embodied Presence in House Environment (REPHE)
Robot Embodied Presence in House Environment is an Innovation project aimed to develop


SciRoc
Bringing Robots into Smart Cities through Competitions


SlideWiki
Large-scale pilots for collaborative OpenCourseWare authoring, multiplatform delivery and Learning Analytics

SPICE
Social cohesion, Participation, and Inclusion through Cultural Engagement

Supporting Editorial Activities at Springer Nature
Supporting Editorial Activities at Springer Nature
TCBL
Textile & Clothing Business Labs

UK Aggregation
Developing the UK Aggregator of Open Access metadata and content from repository systems
UK Aggregation 2
Large scale aggregation of open access research papers
Up2U
Bridging the gap between schools and universities through informal education

VocTeach
Making it quick and easy to locate quality vocational teaching resources.