| |
| |
ClaimSpotter
|
Walkthrough |
The following section presents a tour of ClaimSpotter and illustrates the dialogue instantiated between the interface and the annotator. It also presents the main functionalities of the environment. It is adapted from Bertrand's doctoral thesis. |
Annotation (1/20)
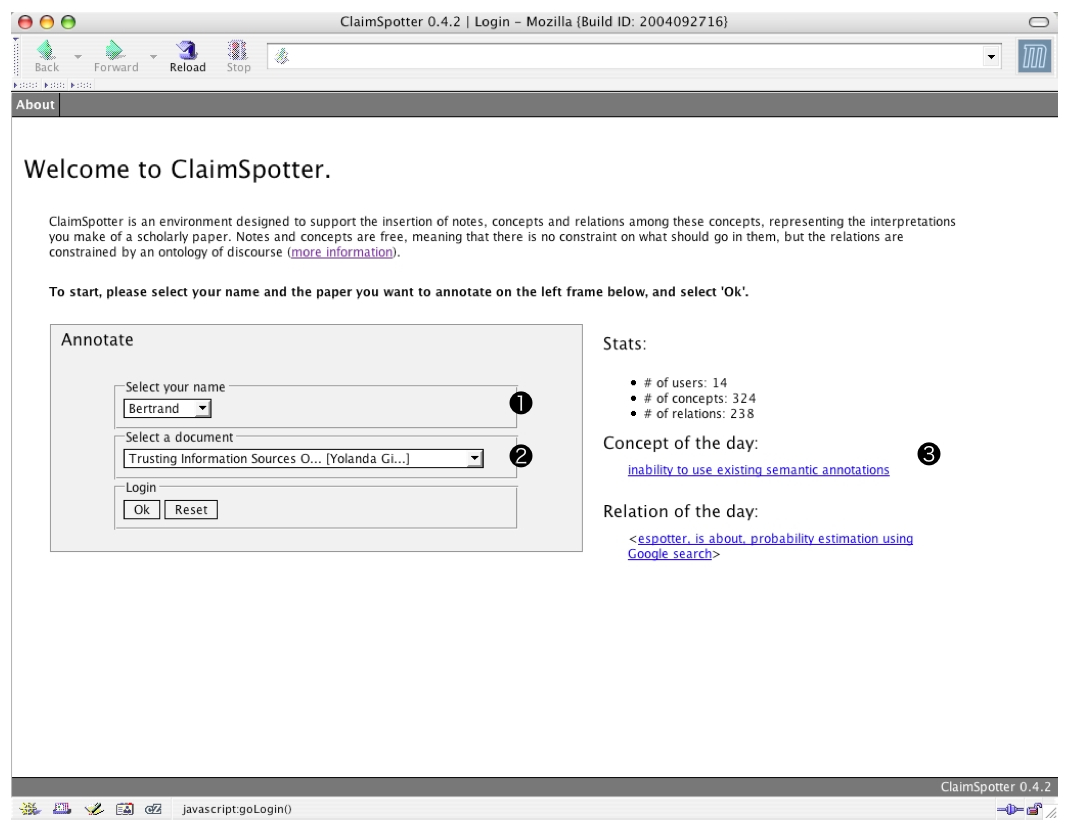
To log in ClaimSpotter, the annotator selects his name (1) and the document (available in XML format) he wishes to annotate (2). On the right side of this screen, a gestalt view gives him a few statistics and the concept and claim of the day (3), a humorous addition to bring life to the environment, ensuring that this screen is different from one day to another.
|
Annotation (2/20)
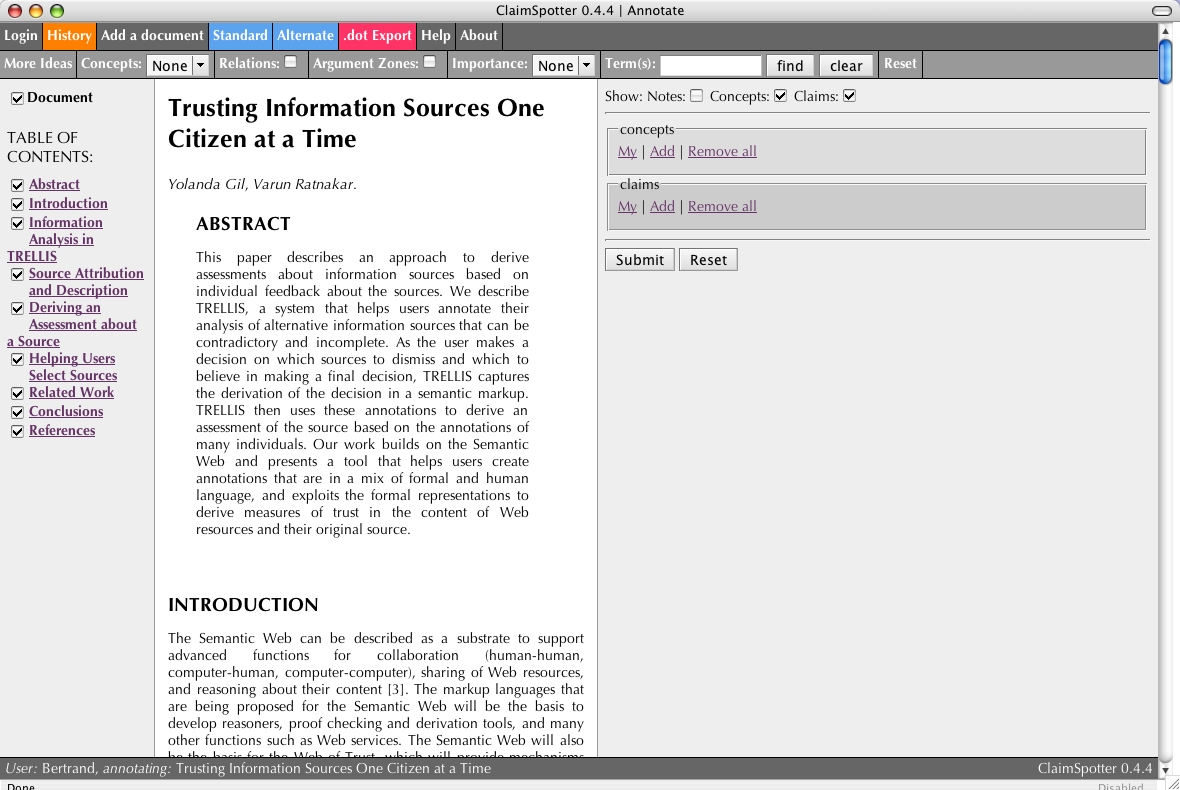
Upon succesful log in, a pristine representation of the document is displayed.
|
Annotation (3/20)
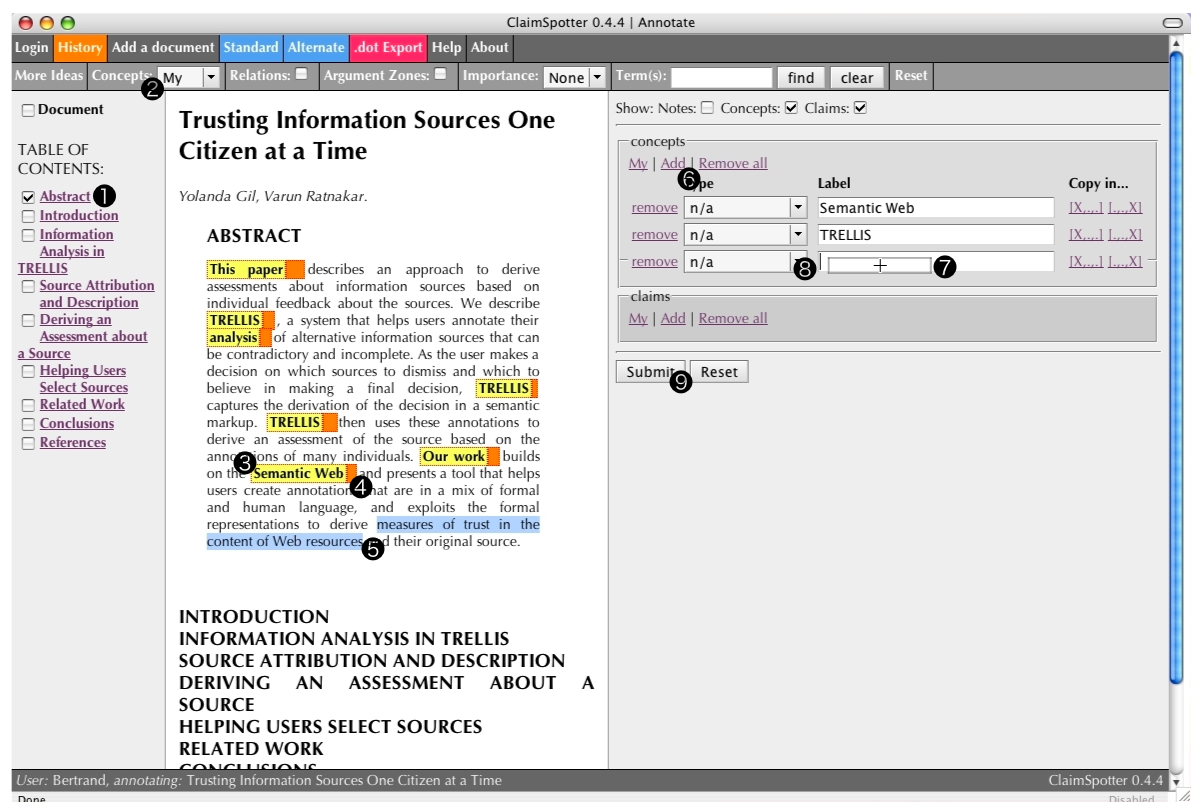
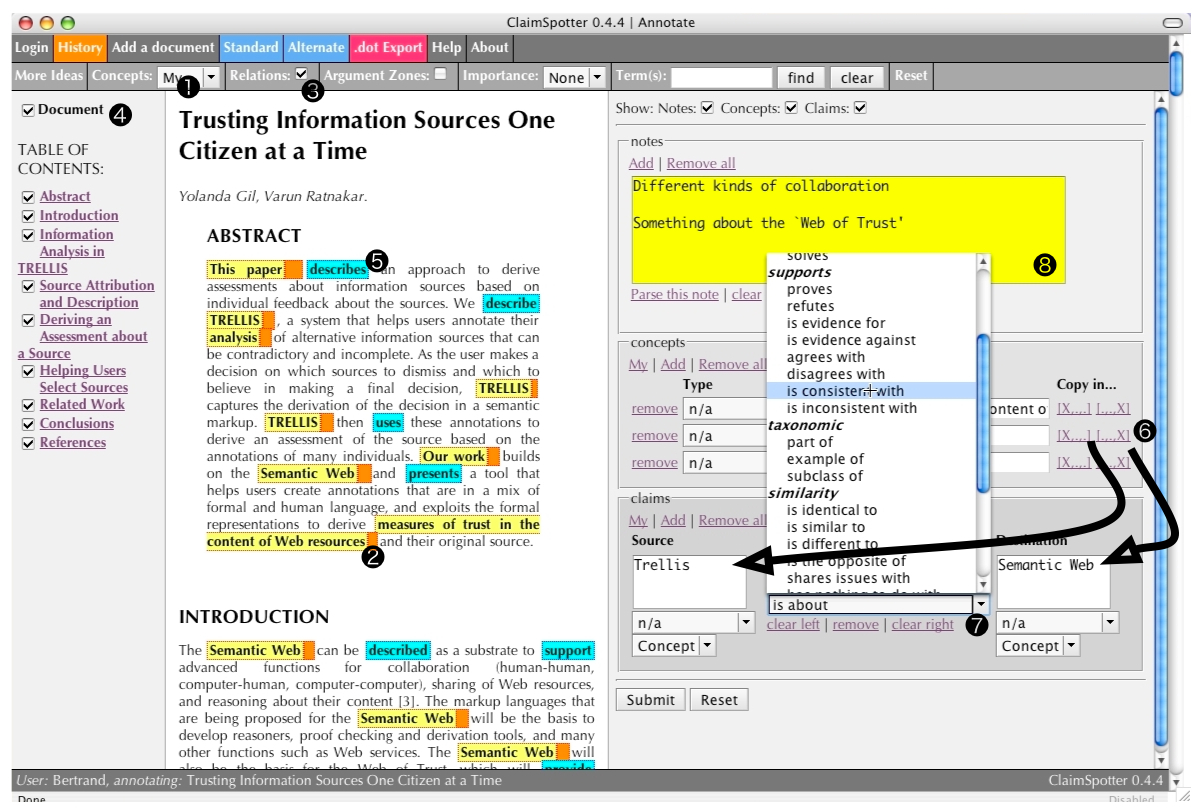
The annotator decides to focus first on the abstract. To this effect, he has hidden the remainder of the document, using the table of contents (1). He has also activated the tags/concepts -that he had defined previously, and that may or not may grounded in this document- matched in this document (2). Each tag can be duplicated (3) in the input form. On the right side of each matched tag, a small orange button activates the corresponding 'History' window (4). The annotator decides to create a tag out of the group of words measures of trust in the content of Web resources (5). To do this, he can either click on the 'add' button of the tags/concepts area of the form (6) and type it, or select words and drag and drop them into an empty tag box (7). Once the tag is dragged and dropped, and classified with an (optional) type (8), it can be submitted (9). Tags already defined for this document and this annotator (e.g., Semantic Web, TRELLIS) are not duplicated. Only measures of trust in the content of Web resources is added to the repository.
|
Annotation (4/20)
Upon submission, the document is rendered in its original view, without any filters applied. The annotator activates his tags again, to see if there is any new matched ones in the document (1): the tag measures of trust in the content of Web resources is now picked by the 'matched concepts' spotting filter (2). He decides to change the view of the document to look for different clues: he activates the 'matched relation' filter (3) in the entire document (4). Relations, just as tags, are 'clickable' (5). The annotator decides to create a claim. He can either type this triple from scratch in the form, or combine the tags he wants to use with the [X,.,.] and [.,.,X] shortcut links (6) and select the relation to use (7). He finally decides to write a note (8) that is saved as a single concept Different kinds of collaboration... Trust, since it does not contain any ScholOnto relation.
|
Annotation (5/20)
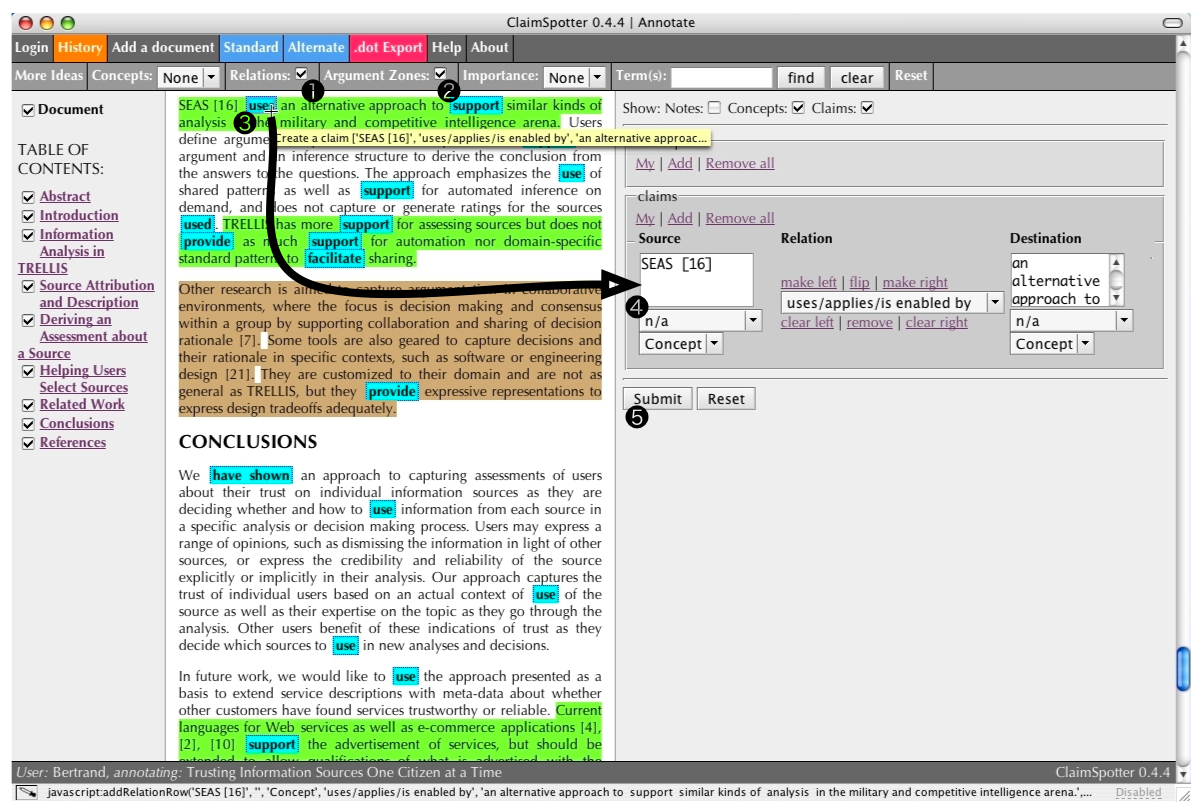
The annotator creates yet another view of the document by activating again the 'matched relations' filter (1) and adding the rhetorical zones filter (red and light green sentences) (2). Clicking on an instance of a ScholOnto relation in the document (3) creates a claim by splitting the sentence into a triple (4) centred on the detected relation: the sentence up to the relation goes on the left side, the sentence from the relation on the right side, and the relation itself, the verb (or a synonym if it is one of the WordNet elements considered), goes in the middle part of the claim. This screenshot shows that not every instance of a ScholOnto relation matched in the document makes an interesting claim triple. In this example, our annotator finds the generated claim triple -[SEAS, uses/applies/is enabled by, an alternative approach to support similar kinds of analysis in the military and competitive intelligence arena] - significant and decides to submit it (5).
|
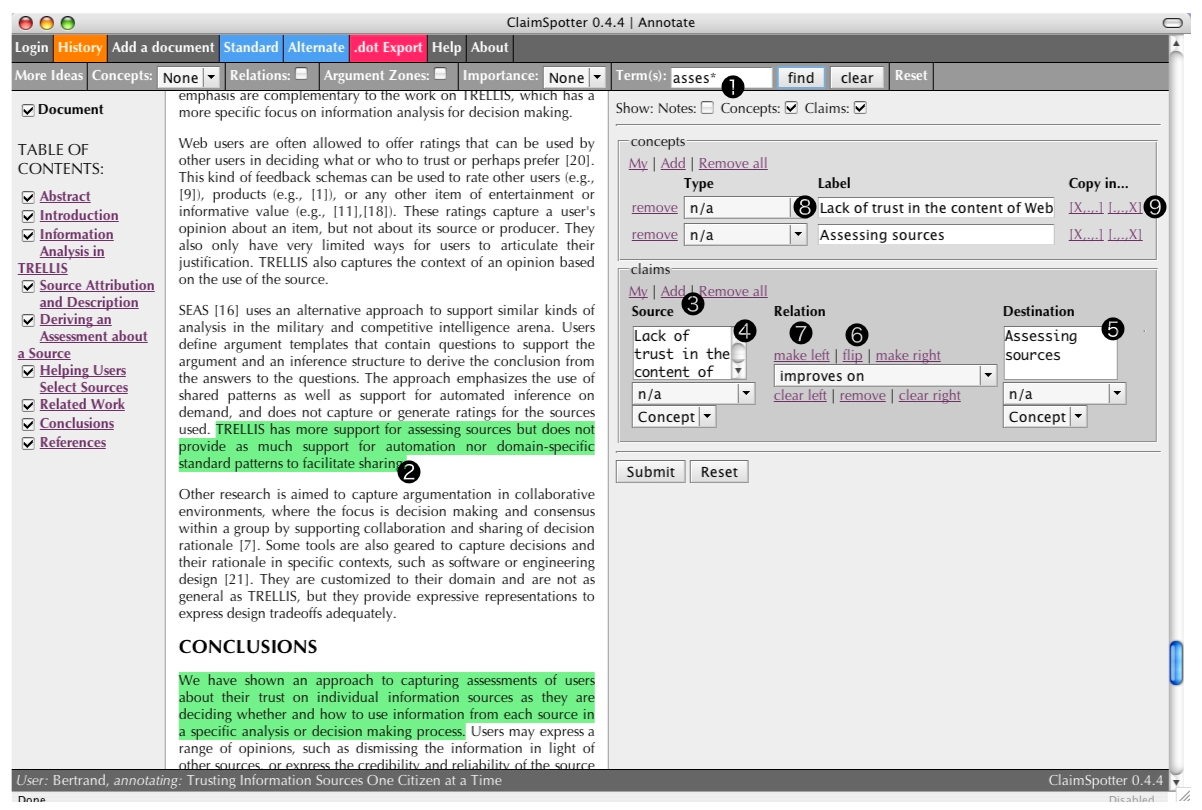
Annotation (6/20)
The annotator decides to focus on the notion of 'assessment'. He activates the 'user-defined' filter (1), which highlights (2) sentences containing the terms matched by this expression (including 'assess', 'assessment'...) He then models a claim by adding a blank claim to the form (3) and typing its constituents (4)(5). He realises that although 'improves on' is the right relation to use, the order in which the tags are arranged is not satisfying. The 'flip' button (6) enables him to switch the left and right tags: {Lack of trust, improves on, Assessing sources} is replaced with a more meaningful {Assessing sources, improves on, Lack of trust}. The left and right objects of a claim can be duplicated in the concepts part of the form (8) with the 'make tag/concept' shortcut links (7), enabling them to be combined in new claims without having to re-type them (using the [X,.,.] and [.,.,X] shortcut links (9)).
|
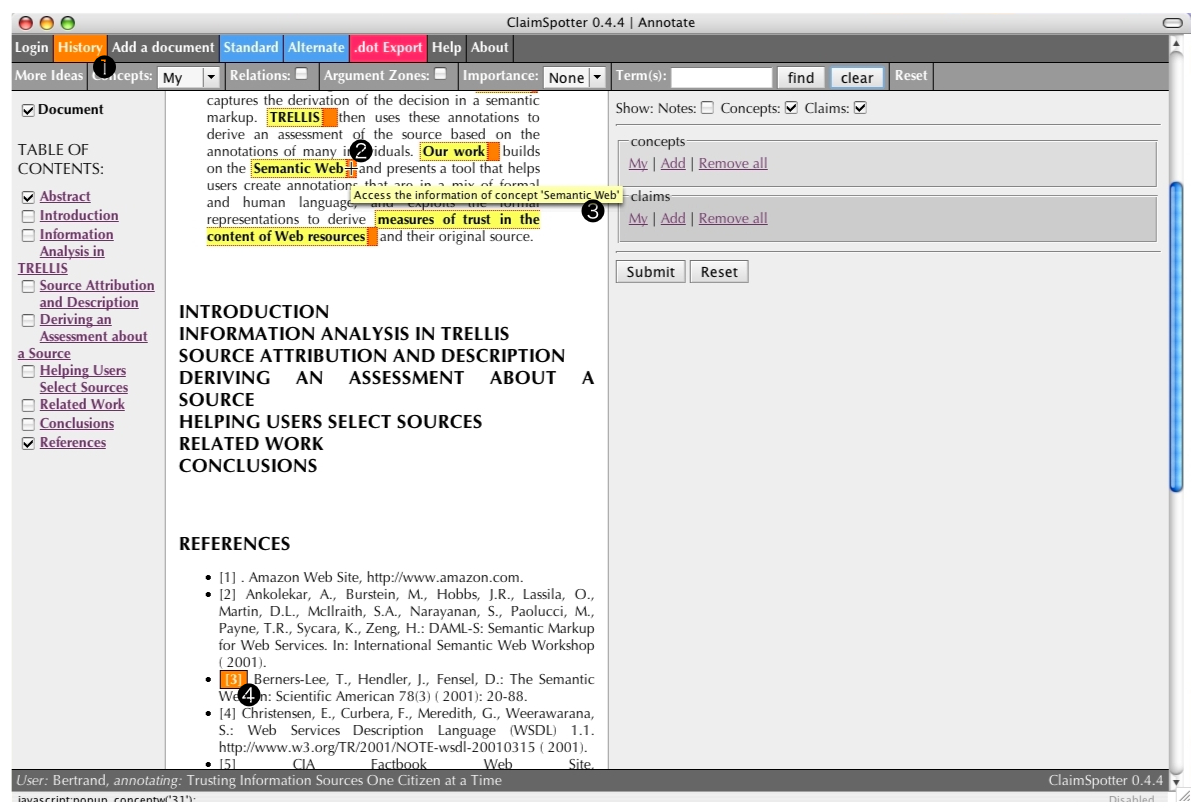
Annotation (7/20)
The history window is accessible from the main toolbar (1). It contains information associated to the current document: its tags, its claims and the documents it cites (using the manually created citations XML file listing the cited documents existing in the ScholOnto repository). It also shows the information associated to any tag/concept, claim, or document cited in the current document. Shortcut links to the relevant history page for the cited documents are provided for each existing concept found in the document (2), with a tool-tip indicating the nature of the information available (3). Links are provided for cited documents (4), enabling the annotator to browse their tags and claims and to reuse them (for instance, by creating a claim between a concept in the current document and a concept in a cited document; more about this later).
|
History (8/20)

Our annotator decides to learn more about the tag Semantic Web (the window displayed above is activated after a click on button (2) in the previous screenshot). The information presented in this window aims at helping annotators answering questions such as 'Who has created this concept?', 'Which document has it been used in, and by who?', and 'Which claims is it involved in?')
The window features the creator of the tag at the top (2) and facilities to import it in the current document as a new tag (3) or as a left or right part of the last claim (if empty) or of a new claim (4). Imported tags/concepts are added to the input form of the main annotation window. It also shows the different contexts the tag has been used in: it has been used already by the current annotator in another document and by one of his peers in another document (5)(6), consciously or not: his peer may have checked if this tag was already existing and if so decided to reuse it, or he may have created his own version without checking beforehand. Since the system does not allow duplicates, both have in effect reused an existing tag. Clicking on the name of a document launches the History window for that document (6). Finally, the claims in which this tag is used are also displayed. Detail of each claim can be accessed (7). 'Import' and 'Copy in' links are also provided (8) (9).
|
History (9/20)
This history window displays detailed information about a claim. It can be used to answer questions such as 'Which concepts are involved in this claim?' and 'Has it been discussed in other claims?' Source and destination tag history pages (1) and additional detail (2) for the claim can be accessed. Import buttons offer quick ways to duplicate the claim in its entirety ([X,X,X]) if the annotator wants to express the same interpretation (3) and to create new claims with either the same source tag ([X,.,.]), relation type ([.,X,.]) or destination tag ([.,.,X]) (4) (these shortcuts leave the other parts of the claim blank). The ScholOnto data model also permits a whole claim triple to be linked from another claim or to another claim. The final set of copying buttons ([[X,X,X],.,.] and [.,.,[X,X,X]]) (5) can be used to copy an entire claim as a left or a right part of another claim.
|
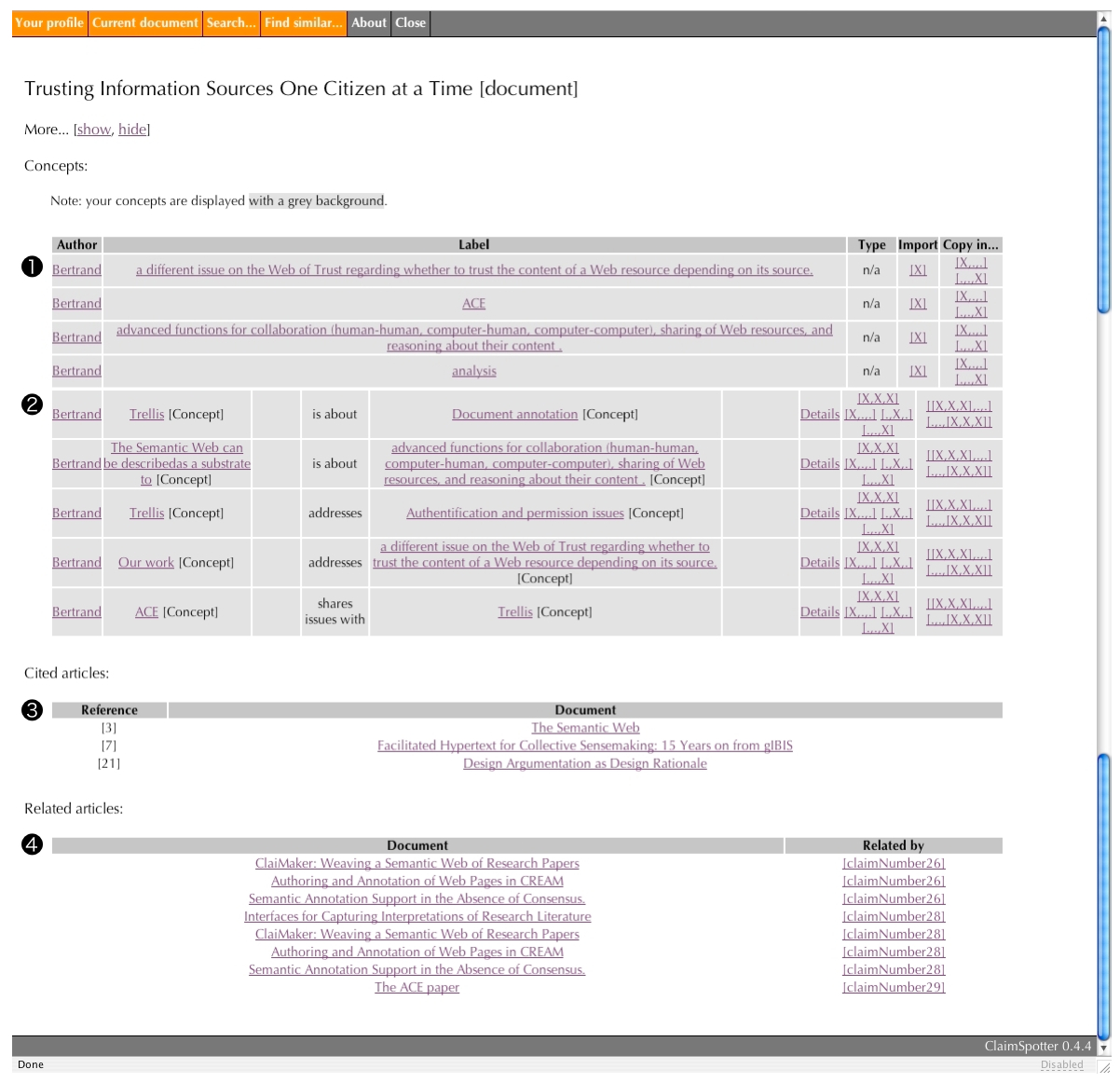
History (10/20)
The annotator activates this history page to reveal a summary view of the document. It includes the tags (1) and claims grounded in the document (2), the (manually specified) cited documents (3) and the related ones (4) (this information is updated automatically.)
|
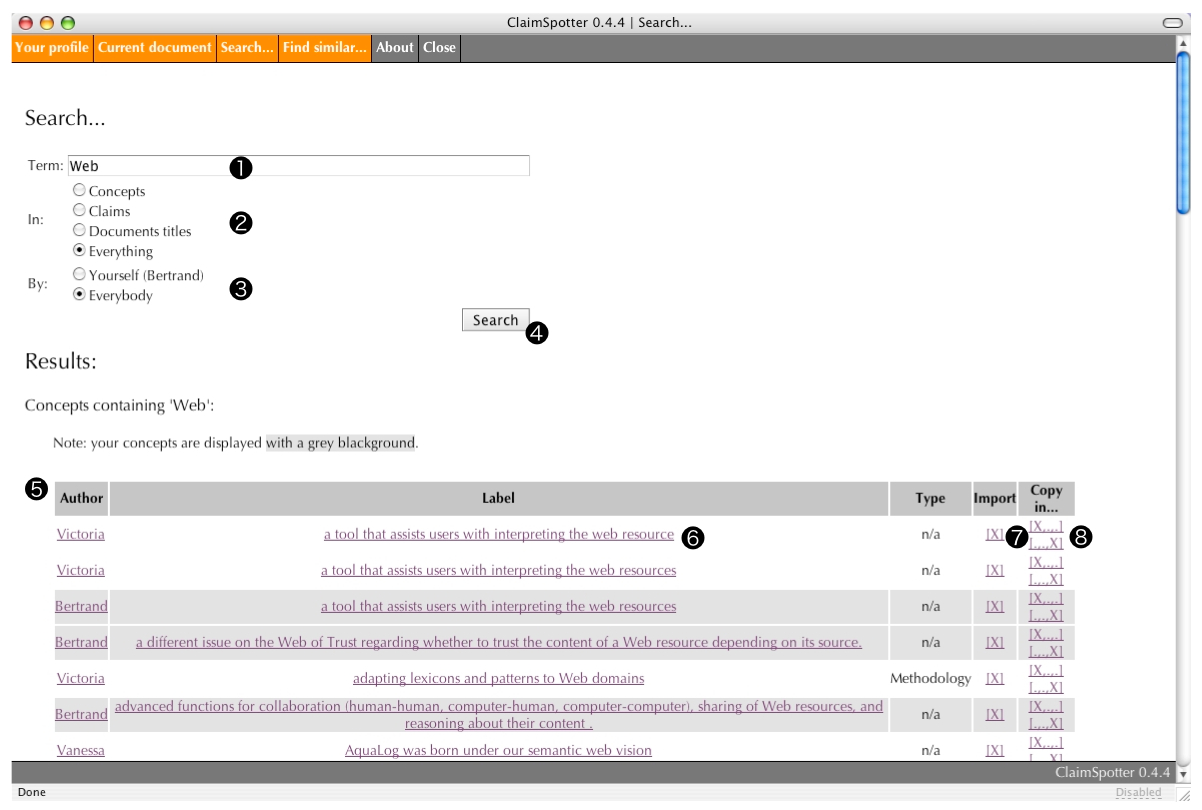
Searching (11/20)
The annotator can use a search window to look for (4) any combination of tag, claim, document title (2), defined by himself or by any of his peers (3), matching the given query expression (1). Results are displayed (5) with the usual layout that includes additional links to the history page of each object returned (6) and possibilities to import or copy the object in the current document input form (in the main window) (7)(8).
|
User profile (12/20)
The user profile displays the information associated to any annotator (1), the concepts he has created (2), his claims (3), and the documents he has annotated (for which he has at least created a concept and/or a claim) (4).
|
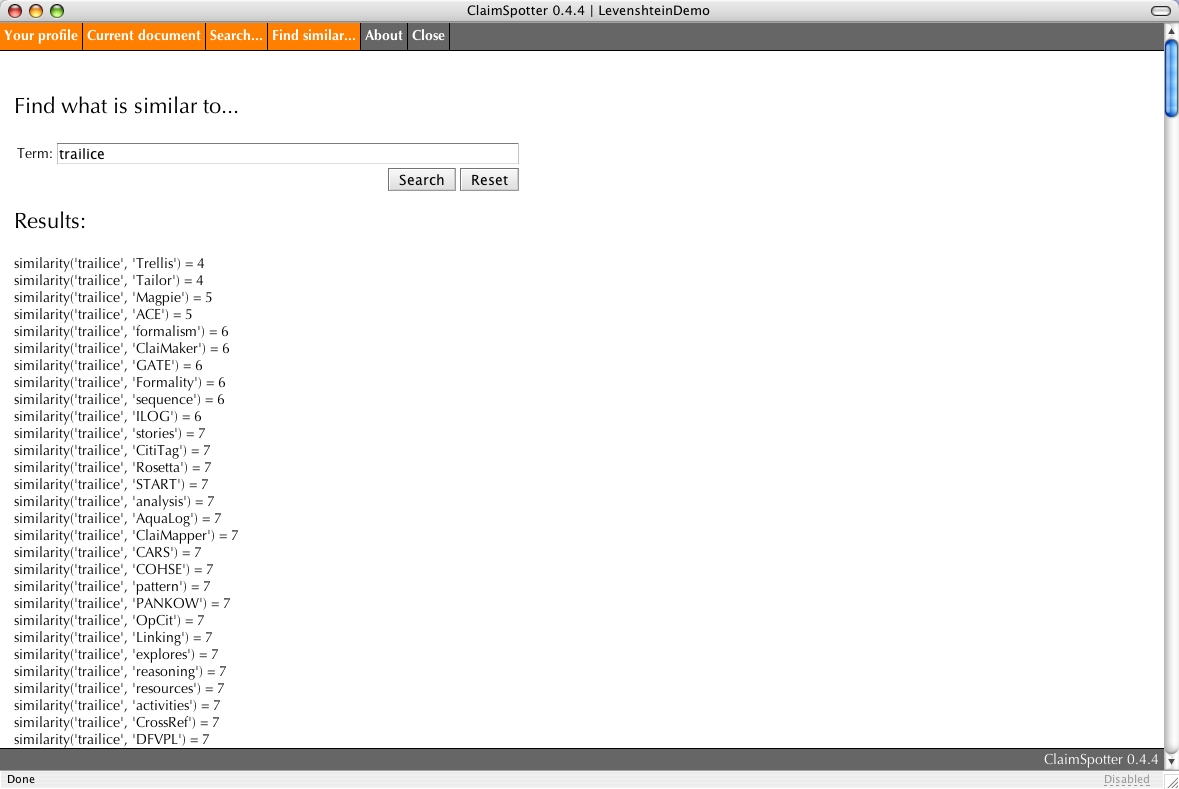
Finding similar... (13/20)
The system does not store duplicate tags: if a tag already exists, it is reused and an instance of it is created for this particular combination of user and document. However, there may be times when one creates a new tag for which there is already a very similar one (that could be advantageously be reused). For instance, an annotator may want to create a concept 'ontologies' when there is already 'ontology' in the repository, or he may misspell the name of an existing project. In such cases, comparing the user input with existing concepts can be helpful. We have developed a module to perform this comparison, using an implementation of the Levenshtein algorithm.
|
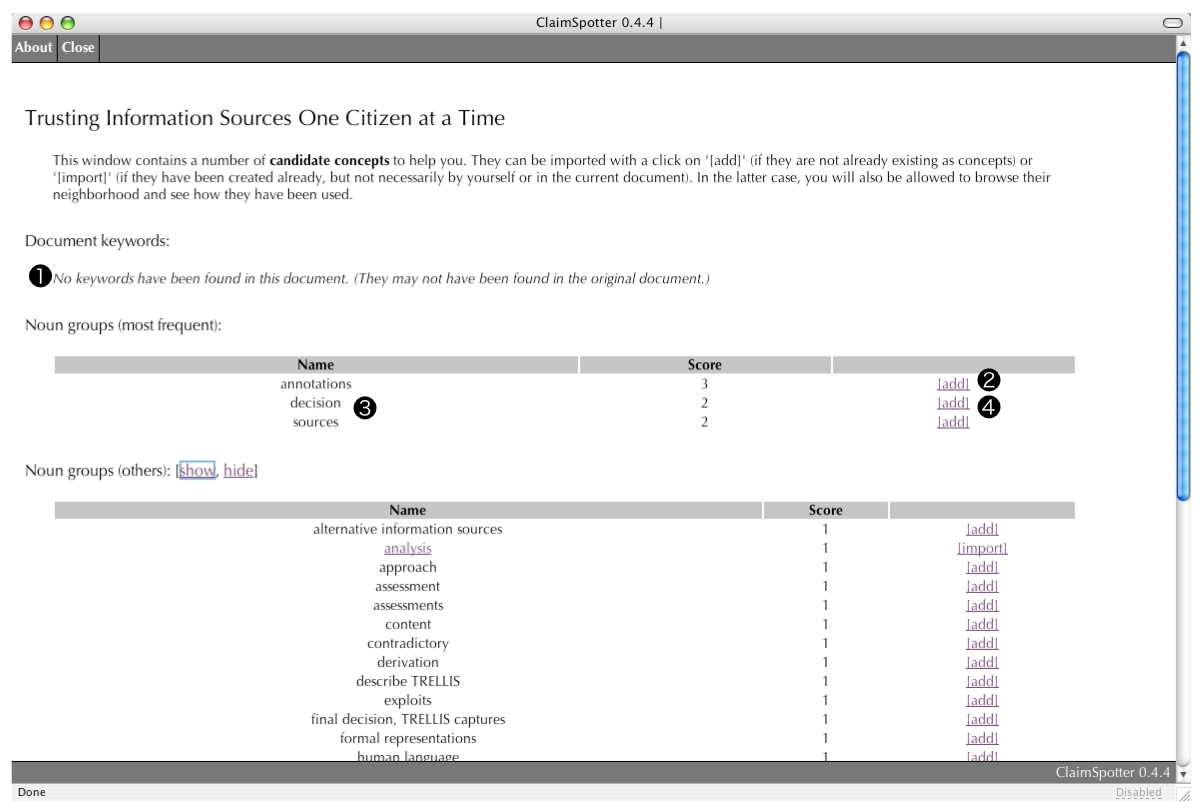
More Ideas (14/20)
The candidate concepts suggested by ClaimSpotter can be accessed via the 'More Ideas' button in the main interface. The 'More Ideas' window lists the document keywords (manually stored in an XML file) and the most frequently found noun groups in the document. Each of these items can be imported by an annotator in the main annotation window with a click on the '[Add]' shortcut button (and edited if desired.) If any of these expressions happens to be a concept already, the '[Add]' button is replaced with '[Import]' and the 'History' for the concept can be accessed (in the example, analysis already exists as a concept). The aim of this module is to give additional ideas to annotators by proposing elements they may have overlooked in their interpretation.
|
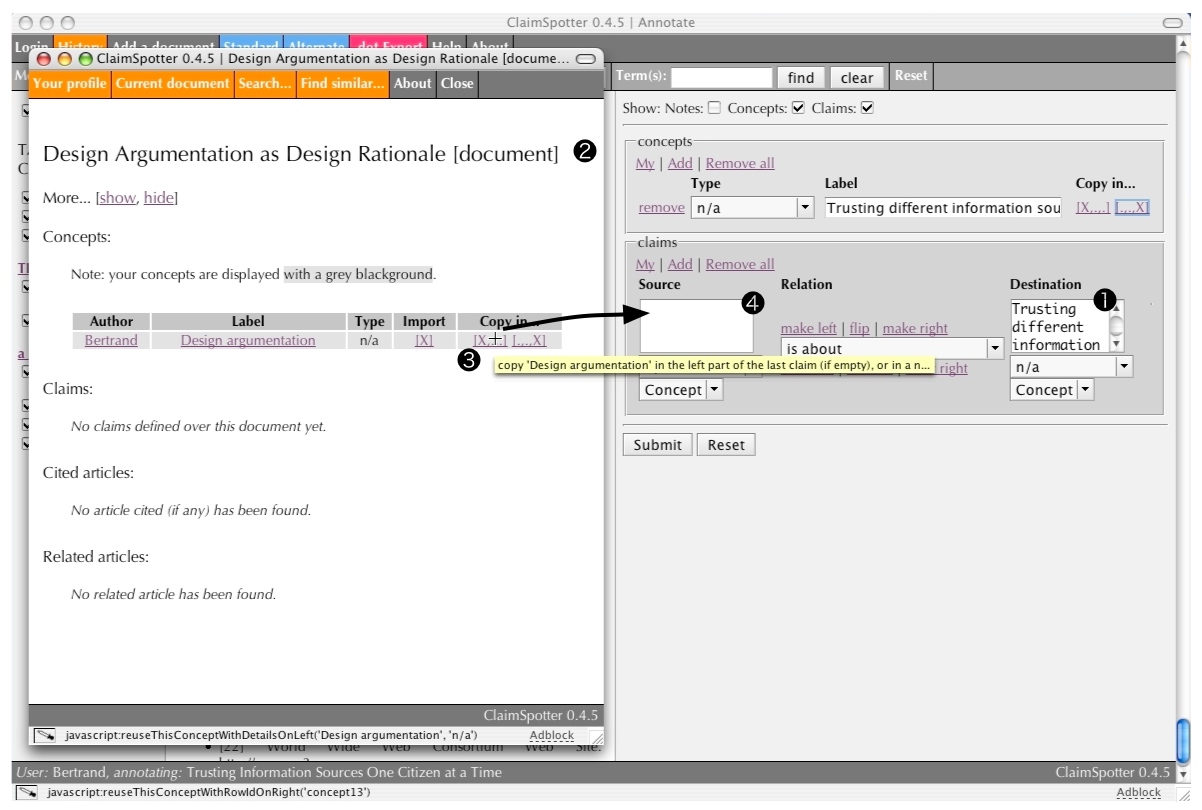
Connecting Documents (15/20)
Documents can be 'connected' in ScholOnto via (i) shared tags or (ii) the definition of claims relating tags defined in different documents. In this example, the annotator creates a claim connecting a tag he has defined earlier, Trusting different information sources (1), and a tag that has been defined in another document (2). Using the shortcuts associated to the remote concept (3), he can combine tags in a claim (4) and submit it. Upon submission, the current document and the document 'Design Argumentation as Design Rationale' (from which the distant tag was imported) become 'connected', or 'semantically related,' in the ScholOnto repository.
|
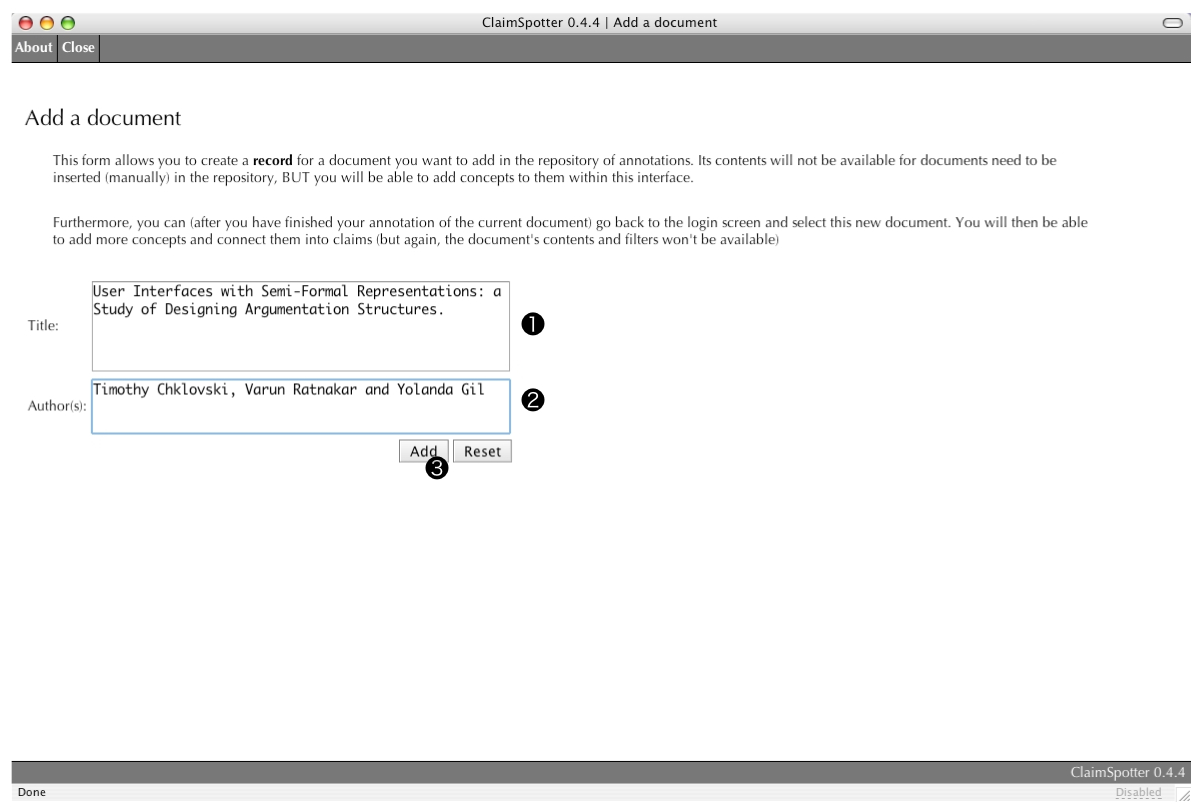
Adding a Document (16/20)
The addition of external document (which must be written in the XML language used by ClaimSpotter) is not permitted in the current version of ClaimSpotter. Instead, stubs can be created to represent them, enabling concepts to be defined and attached to them.
|
Views (17/20)
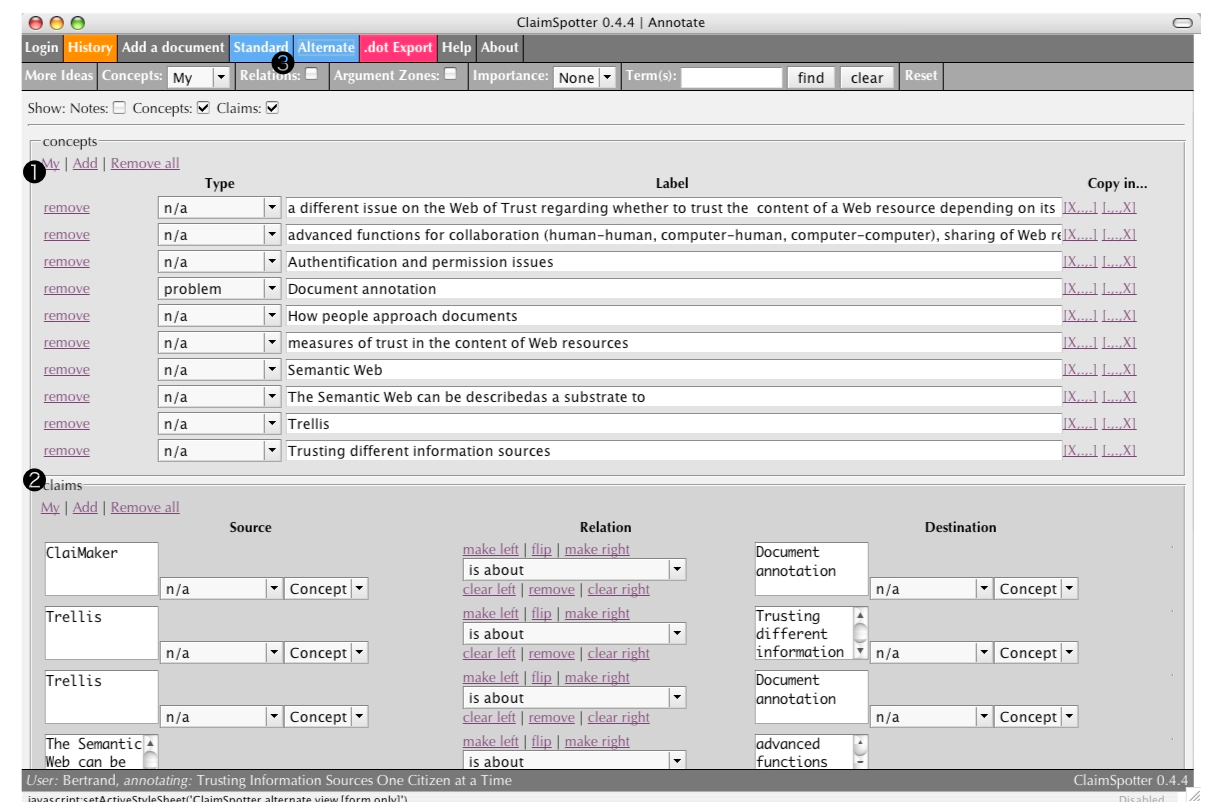
The view mechanism is a recent addition to ClaimSpotter. It experiments with the idea of displaying information in multiple ways, to suit different needs of annotators. This alternate view hides the document and provides more space to create tags (1) and articulate them into claims (2). This view, focussing more on the annotation aspect and less on the interaction with the document and the 'discovery' of ideas, may be more suitable to reflective work, when annotators know what they want to record and look for the best way to express it in the formalism. It is possible to switch to the standard view at any time using the buttons in the general toolbar (3).
|
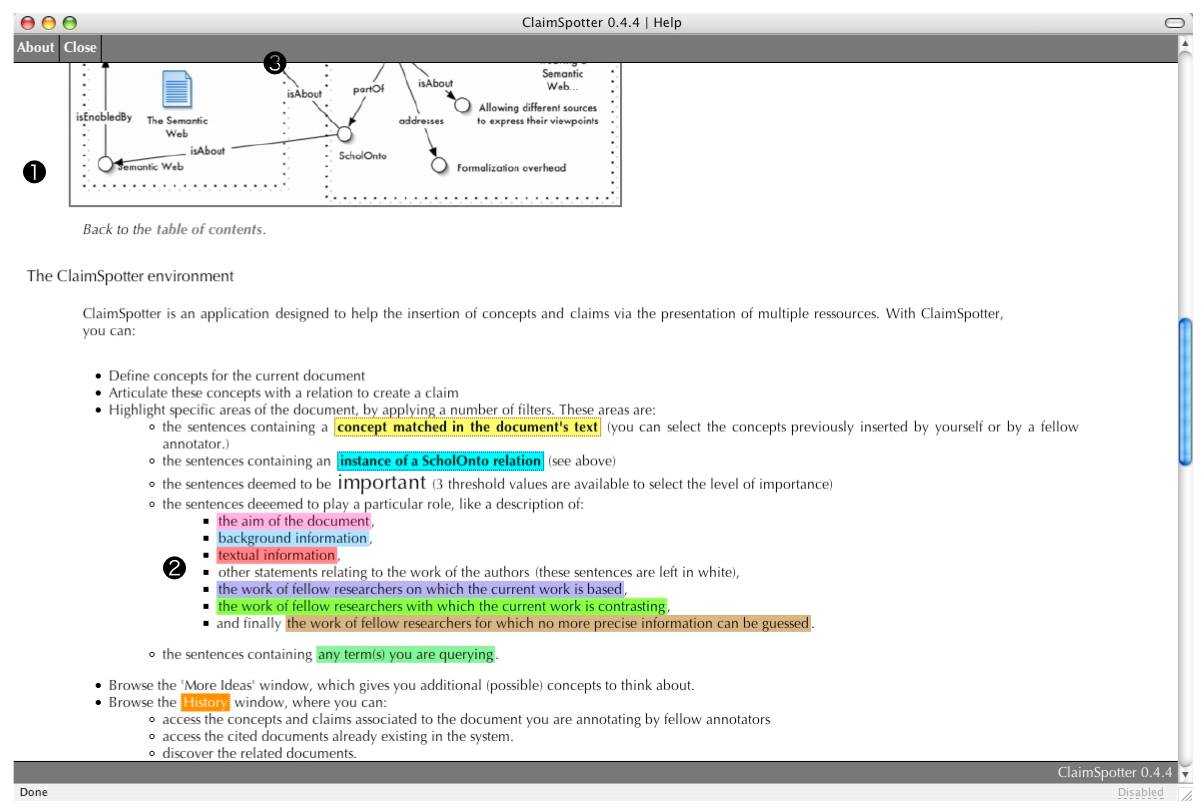
Help (18/20)
A 'Help' screen is provided, containing information about the ScholOnto language (1), the key for the different colours used by the spotting filters (2) and instructions to perform common tasks such as defining a tag or creating a claim.
|
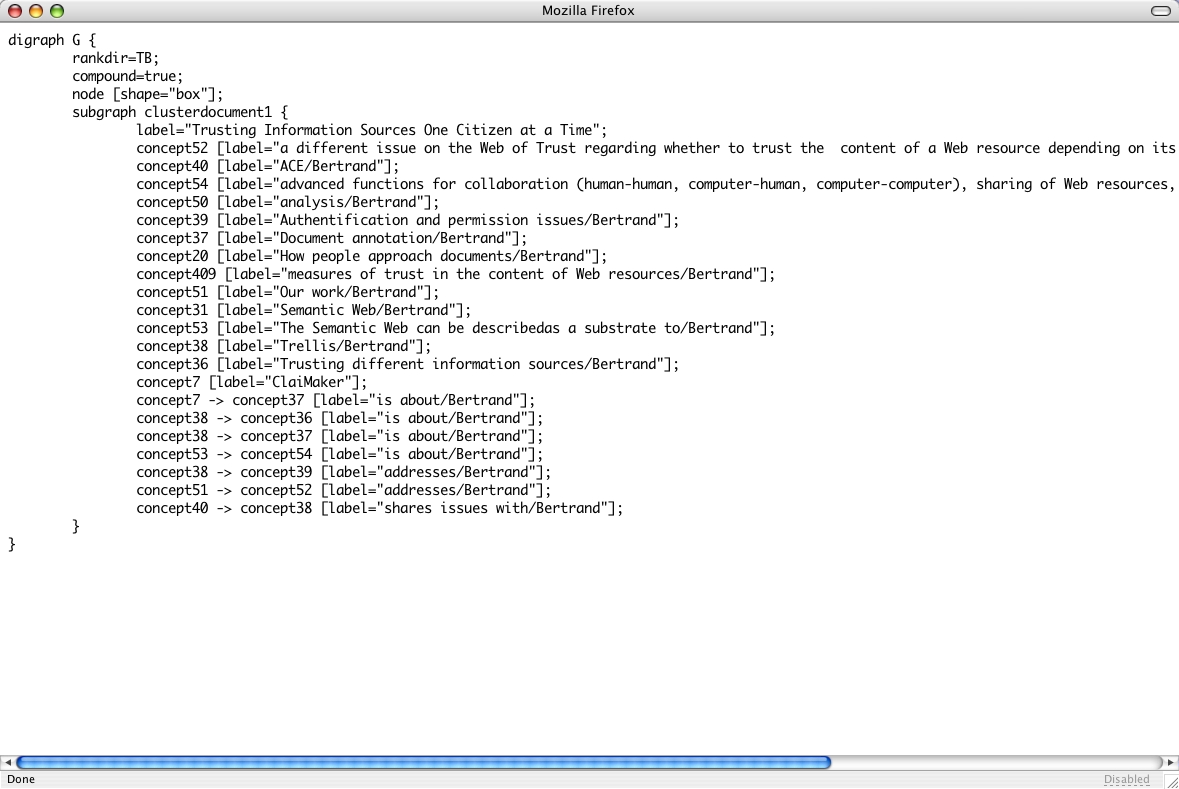
Exporting as a Graph (19/20)
An export option is also available from the interface. Clicking on the 'Export' button generates text output that can be saved in a file and loaded in a graph application to be visualised. The generated graph-file takes as input any combination of document and annotator, and generates a .dot file.
|
Notifications (20/20)
Notification is supported via the definition of RSS feeds. They are available for any:
- Concept: the feed contains answers to questions 'Who has reused this concept?', 'For which document?' and 'Has it been used in a claim?'
- Claim: the feed contains the latest claims reusing it. Annotators are notified if one of their claims is challenged.
- Document: the feed contains the newest concepts and claims defined over it. Annotators are notified of any added interpretation.
- Annotator: the feed contains the newest concepts and claims submitted by this annotator. The models of a particular annotator can be tracked.
|
Last updated by Bertrand Sereno on 1 May 2007
|
| |